Langfuse Datasets Cookbook
In this cookbook, we'll iterate on systems prompts with the goal of getting only the capital of a given country. We use Langfuse datasets, to store a list of example inputs and expected outputs.
This is a very simple example, you can run experiments on any LLM application that you either trace with the Langfuse SDKs (opens in a new tab) (Python, JS/TS) or via one of our integrations (opens in a new tab) (e.g. Langchain).
Simple example application
- Model: gpt-3.5-turbo
- Input: country name
- Output: capital
- Evaluation: exact match of completion and ground truth
- Experiment on: system prompt
Setup
%pip install langfuse openai langchain --upgradeimport os
# get keys for your project from https://cloud.langfuse.com
os.environ["LANGFUSE_PUBLIC_KEY"] = ""
os.environ["LANGFUSE_SECRET_KEY"] = ""
# your openai key
os.environ["OPENAI_API_KEY"] = ""
# Your host, defaults to https://cloud.langfuse.com
# For US data region, set to "https://us.cloud.langfuse.com"
# os.environ["LANGFUSE_HOST"] = "http://localhost:3000"# import
from langfuse import Langfuse
import openai
# init
langfuse = Langfuse()Create a dataset
langfuse.create_dataset(name="capital_cities");Items
Load local items into the Langfuse dataset. Alternatively you can add items from production via the Langfuse UI.
# example items, could also be json instead of strings
local_items = [
{"input": {"country": "Italy"}, "expected_output": "Rome"},
{"input": {"country": "Spain"}, "expected_output": "Madrid"},
{"input": {"country": "Brazil"}, "expected_output": "Brasília"},
{"input": {"country": "Japan"}, "expected_output": "Tokyo"},
{"input": {"country": "India"}, "expected_output": "New Delhi"},
{"input": {"country": "Canada"}, "expected_output": "Ottawa"},
{"input": {"country": "South Korea"}, "expected_output": "Seoul"},
{"input": {"country": "Argentina"}, "expected_output": "Buenos Aires"},
{"input": {"country": "South Africa"}, "expected_output": "Pretoria"},
{"input": {"country": "Egypt"}, "expected_output": "Cairo"},
]# Upload to Langfuse
for item in local_items:
langfuse.create_dataset_item(
dataset_name="capital_cities",
# any python object or value
input=item["input"],
# any python object or value, optional
expected_output=item["expected_output"]
)Define application and run experiments
We implement the application in two ways to demonstrate how it's done
- Custom LLM app using e.g. OpenAI SDK, traced with Langfuse Python SDK
- Langchain Application, traced via native Langfuse integration
# we use a very simple eval here, you can use any eval library
# see https://langfuse.com/docs/scores/model-based-evals for details
def simple_evaluation(output, expected_output):
return output == expected_outputCustom app
from datetime import datetime
def run_my_custom_llm_app(input, system_prompt):
messages = [
{"role":"system", "content": system_prompt},
{"role":"user", "content": input["country"]}
]
generationStartTime = datetime.now()
openai_completion = openai.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages
).choices[0].message.content
langfuse_generation = langfuse.generation(
name="guess-countries",
input=messages,
output=openai_completion,
model="gpt-3.5-turbo",
start_time=generationStartTime,
end_time=datetime.now()
)
return openai_completion, langfuse_generationdef run_experiment(experiment_name, system_prompt):
dataset = langfuse.get_dataset("capital_cities")
for item in dataset.items:
completion, langfuse_generation = run_my_custom_llm_app(item.input, system_prompt)
item.link(langfuse_generation, experiment_name) # pass the observation/generation object or the id
langfuse_generation.score(
name="exact_match",
value=simple_evaluation(completion, item.expected_output)
)run_experiment(
"famous_city",
"The user will input countries, respond with the most famous city in this country"
)
run_experiment(
"directly_ask",
"What is the capital of the following country?"
)
run_experiment(
"asking_specifically",
"The user will input countries, respond with only the name of the capital"
)
run_experiment(
"asking_specifically_2nd_try",
"The user will input countries, respond with only the name of the capital. State only the name of the city."
)Langchain application
from datetime import datetime
from langchain.chat_models import ChatOpenAI
from langchain.chains import LLMChain
from langchain.schema import AIMessage, HumanMessage, SystemMessage
def run_my_langchain_llm_app(input, system_message, callback_handler):
# needs to include {country}
messages = [
SystemMessage(
content=system_message
),
HumanMessage(
content=input
),
]
chat = ChatOpenAI(callbacks=[callback_handler])
completion = chat(messages)
return completion.contentdef run_langchain_experiment(experiment_name, system_message):
dataset = langfuse.get_dataset("capital_cities")
for item in dataset.items:
handler = item.get_langchain_handler(run_name=experiment_name)
completion = run_my_langchain_llm_app(item.input["country"], system_message, handler)
handler.root_span.score(
name="exact_match",
value=simple_evaluation(completion, item.expected_output)
)run_langchain_experiment(
"langchain_famous_city",
"The user will input countries, respond with the most famous city in this country"
)
run_langchain_experiment(
"langchain_directly_ask",
"What is the capital of the following country?"
)
run_langchain_experiment(
"langchain_asking_specifically",
"The user will input countries, respond with only the name of the capital"
)
run_langchain_experiment(
"langchain_asking_specifically_2nd_try",
"The user will input countries, respond with only the name of the capital. State only the name of the city."
)Evaluate experiments in Langfuse UI
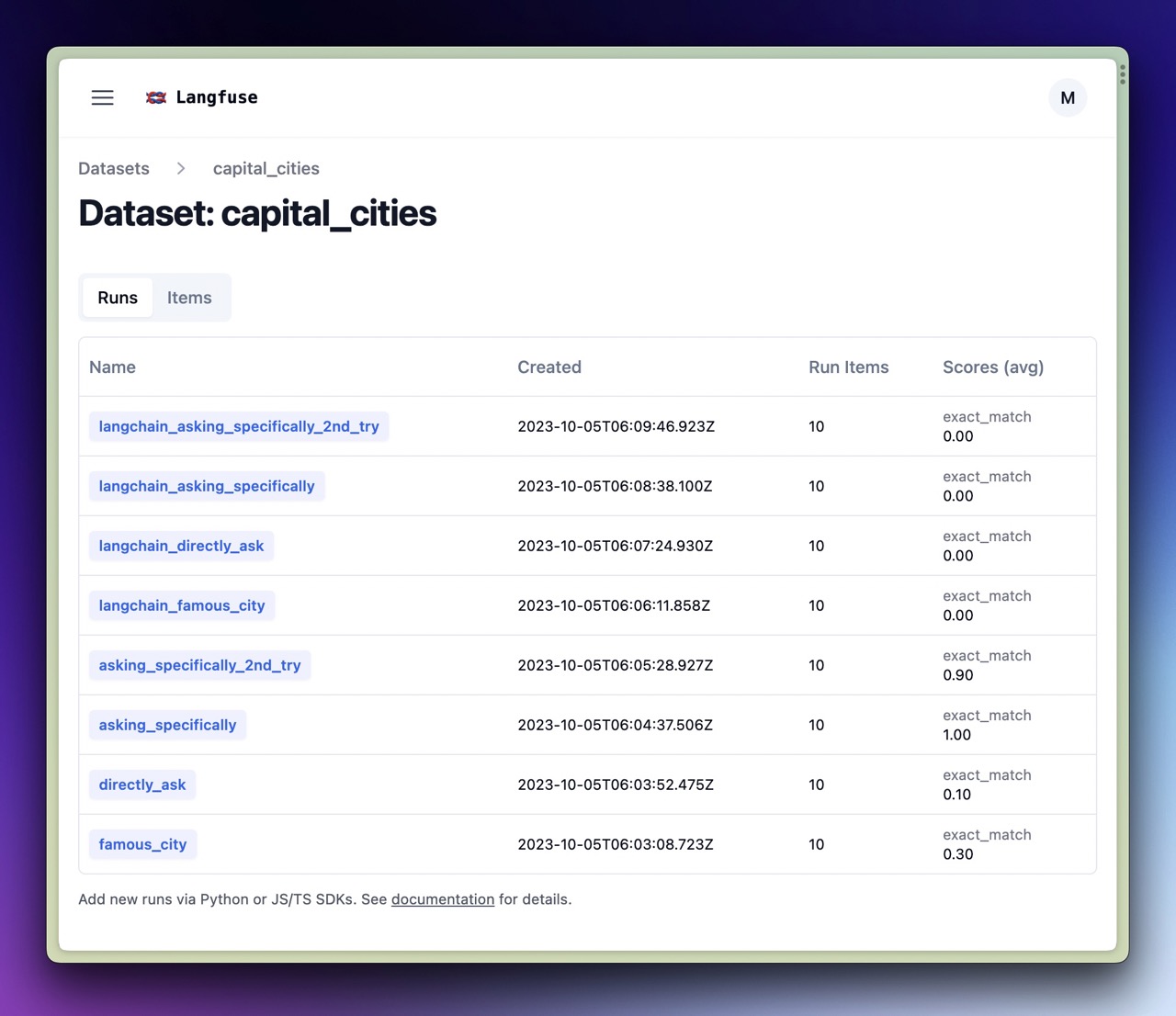
- Average scores per experiment run
- Browse each run for an individual item
- Look at traces to debug issues