Datasets
Datasets in Langfuse are a collection of inputs (and expected outputs) of an LLM application. They are used to benchmark new releases before deployment to production. Datasets can be incrementally created from new edge cases found in production.
For an end-to-end example, check out the Datasets Notebook (Python).
Creating a dataset
Datasets have a name which is unique within a project.
langfuse.create_dataset(name="<dataset_name>")See low-level SDK docs for details on how to initialize the Python client.
Create new dataset items
Individual items can be added to a dataset by providing the input and optionally the expected output.
langfuse.create_dataset_item(
dataset_name="<dataset_name>",
# any python object or value
input={
"text": "hello world"
},
# any python object or value, optional
expected_output={
"text": "hello world"
}
)See low-level SDK docs for details on how to initialize the Python client.
Create items from production data
In the UI, use + Add to dataset on any observation (span, event, generation) of a production trace.
Edit/archive items
In the UI, you can edit or archive items by clicking on the item in the table. Archiving items will remove them from future experiment runs.
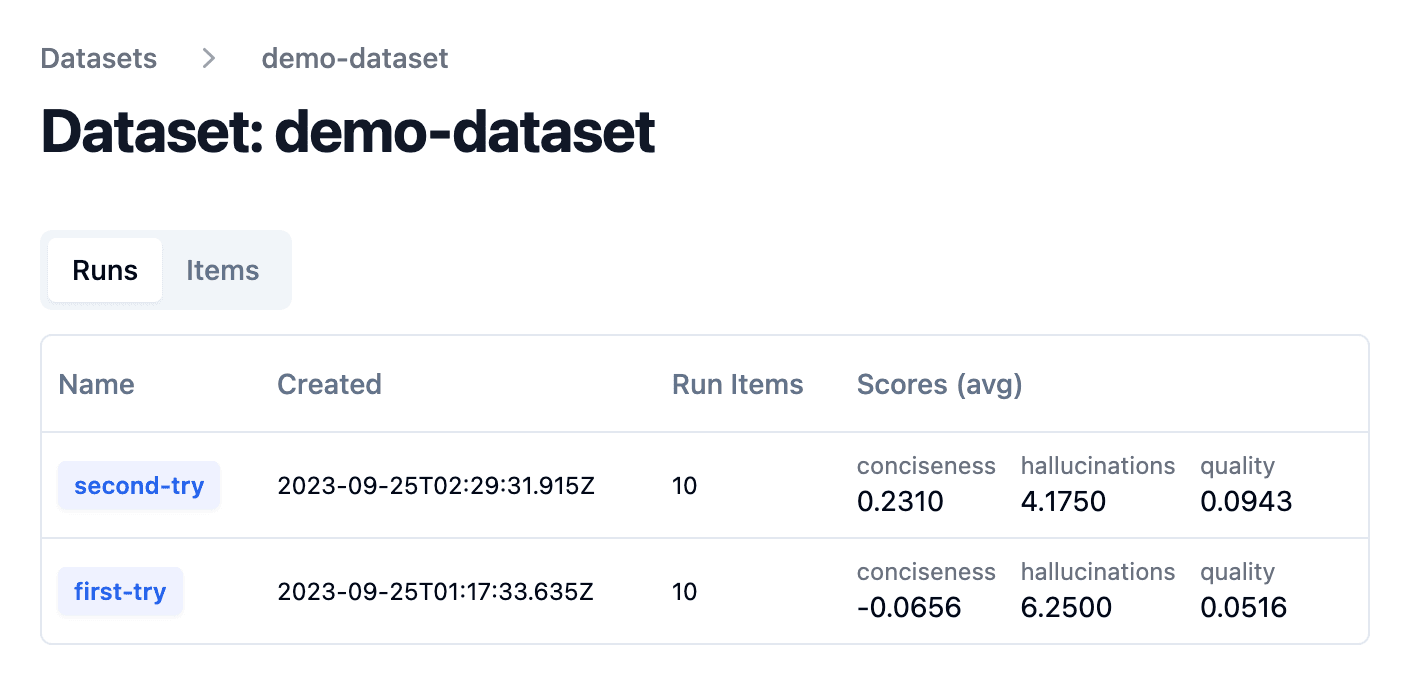
Run experiment on a dataset
When running an experiment on a dataset, the application that shall be tested is executed for each item in the dataset. The execution trace is then linked to the dataset item. This allows to compare different runs of the same application on the same dataset. Each experiment is identified by a run_name.
Optionally, the output of the application can be evaluated to compare different runs more easily. Use any evaluation function and add a score to the observation. More details on scores/evals here.
dataset = langfuse.get_dataset("<dataset_name>")
for item in dataset.items:
# execute application function and get Langfuse parent observation (span/generation/event)
# output also returned as it is used to evaluate the run
generation, output = my_llm_application.run(item.input)
# link the execution trace to the dataset item and give it a run_name
item.link(generation, "<run_name>")
# optionally, evaluate the output to compare different runs more easily
generation.score(
name="<example_eval>",
# any float value
value=my_eval_fn(
item.input,
output,
item.expected_output
)
)See low-level SDK docs for details on how to initialize the Python client.
Evaluate dataset runs
After each experiment run on a dataset, you can check the aggregated score in the dataset runs table.