Evaluate Langfuse LLM Traces with UpTrain
UpTrain's open-source library offers a series of evaluation metrics to assess LLM applications.
This notebook demonstrates how to run UpTrain's evaluation metrics on the traces generated by Langfuse. In Langfuse you can then monitor these scores over time or use them to compare different experiments.
Setup
You can get your Langfuse API keys here (opens in a new tab) and OpenAI API key here (opens in a new tab)
%pip install langfuse datasets uptrain litellm openai --upgradeimport os
# get keys for your project from https://cloud.langfuse.com
os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-lf-..."
os.environ["LANGFUSE_SECRET_KEY"] = "sk-lf-..."
os.environ["LANGFUSE_HOST"] = "https://cloud.langfuse.com" # for EU data region
# os.environ["LANGFUSE_HOST"] = "https://us.cloud.langfuse.com" # for US data region
# your openai key
os.environ["OPENAI_API_KEY"] = ""Sample Dataset
We use this dataset to represent traces (opens in a new tab) that you have logged to Langfuse. In a production environment, you would use your own data.
data = [
{
"question": "What are the symptoms of a heart attack?",
"context": "A heart attack, or myocardial infarction, occurs when the blood supply to the heart muscle is blocked. Chest pain is a good symptom of heart attack, though there are many others.",
"response": "Symptoms of a heart attack may include chest pain or discomfort, shortness of breath, nausea, lightheadedness, and pain or discomfort in one or both arms, the jaw, neck, or back."
},
{
"question": "Can stress cause physical health problems?",
"context": "Stress is the body's response to challenges or threats. Yes, chronic stress can contribute to various physical health problems, including cardiovascular issues.",
"response": "Yes, chronic stress can contribute to various physical health problems, including cardiovascular issues, and a weakened immune system."
},
{
'question': "What are the symptoms of a heart attack?",
'context': "A heart attack, or myocardial infarction, occurs when the blood supply to the heart muscle is blocked. Symptoms of a heart attack may include chest pain or discomfort, shortness of breath and nausea.",
'response': "Heart attack symptoms are usually just indigestion and can be relieved with antacids."
},
{
'question': "Can stress cause physical health problems?",
'context': "Stress is the body's response to challenges or threats. Yes, chronic stress can contribute to various physical health problems, including cardiovascular issues.",
'response': "Stress is not real, it is just imaginary!"
}
]Run Evaluations using UpTrain
We have used the following 3 metrics from UpTrain's open-source library:
-
Context Relevance (opens in a new tab): Evaluates how relevant the retrieved context is to the question specified.
-
Factual Accuracy (opens in a new tab): Evaluates whether the response generated is factually correct and grounded by the provided context.
-
Response Completeness (opens in a new tab): Evaluates whether the response has answered all the aspects of the question specified.
You can look at the complete list of UpTrain's supported metrics here (opens in a new tab)
from uptrain import EvalLLM, Evals
import json
import pandas as pd
eval_llm = EvalLLM(openai_api_key=os.environ["OPENAI_API_KEY"])
res = eval_llm.evaluate(
data = data,
checks = [Evals.CONTEXT_RELEVANCE, Evals.FACTUAL_ACCURACY, Evals.RESPONSE_COMPLETENESS]
)Using Langfuse
There are two main ways to run evaluations:
-
Score each Trace (in development): This means you will run the UpTrain evaluations for each trace item.
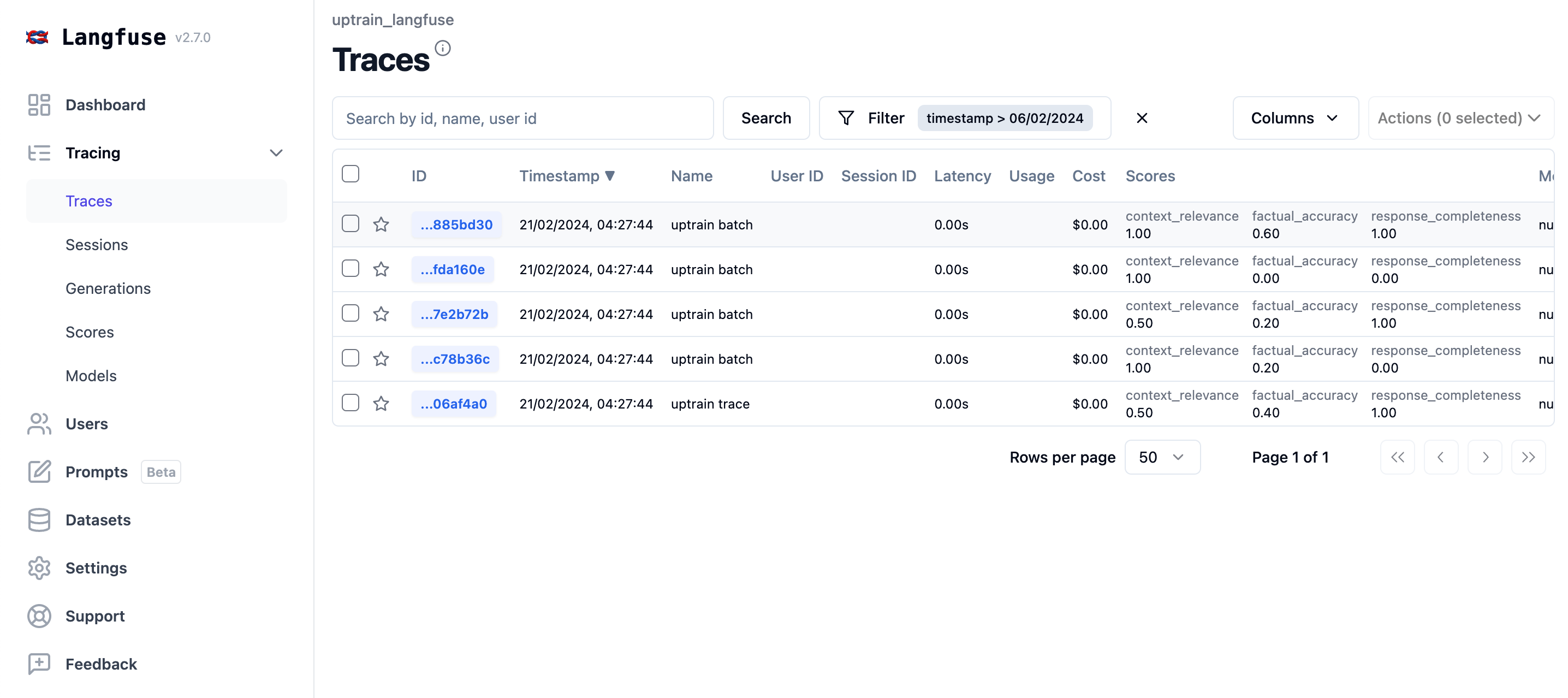
-
Score in Batches (in production): In this method we will simulate fetching production traces on a periodic basis to score them using the UpTrain evaluators. Often, you'll want to sample the traces instead of scoring all of them to control evaluation costs.
Development: Score each trace while it's created
from langfuse import Langfuse
langfuse = Langfuse()
langfuse.auth_check()We mock the instrumentation of your application by using the sample dataset. See the quickstart (opens in a new tab) to integrate Langfuse with your application.
# start a new trace when you get a question
question = data[0]['question']
trace = langfuse.trace(name = "uptrain trace")
# retrieve the relevant chunks
# chunks = get_similar_chunks(question)
context = data[0]['context']
# pass it as span
trace.span(
name = "retrieval", input={'question': question}, output={'context': context}
)
# use llm to generate a answer with the chunks
# answer = get_response_from_llm(question, chunks)
response = data[0]['response']
trace.span(
name = "generation", input={'question': question, 'context': context}, output={'response': response}
)We reuse the scores previously calculated for the traces in the sample dataset. In development, you would run the UpTrain evaluations for the single trace as it's created.
trace.score(name='context_relevance', value=res[0]['score_context_relevance'])
trace.score(name='factual_accuracy', value=res[0]['score_factual_accuracy'])
trace.score(name='response_completeness', value=res[0]['score_response_completeness'])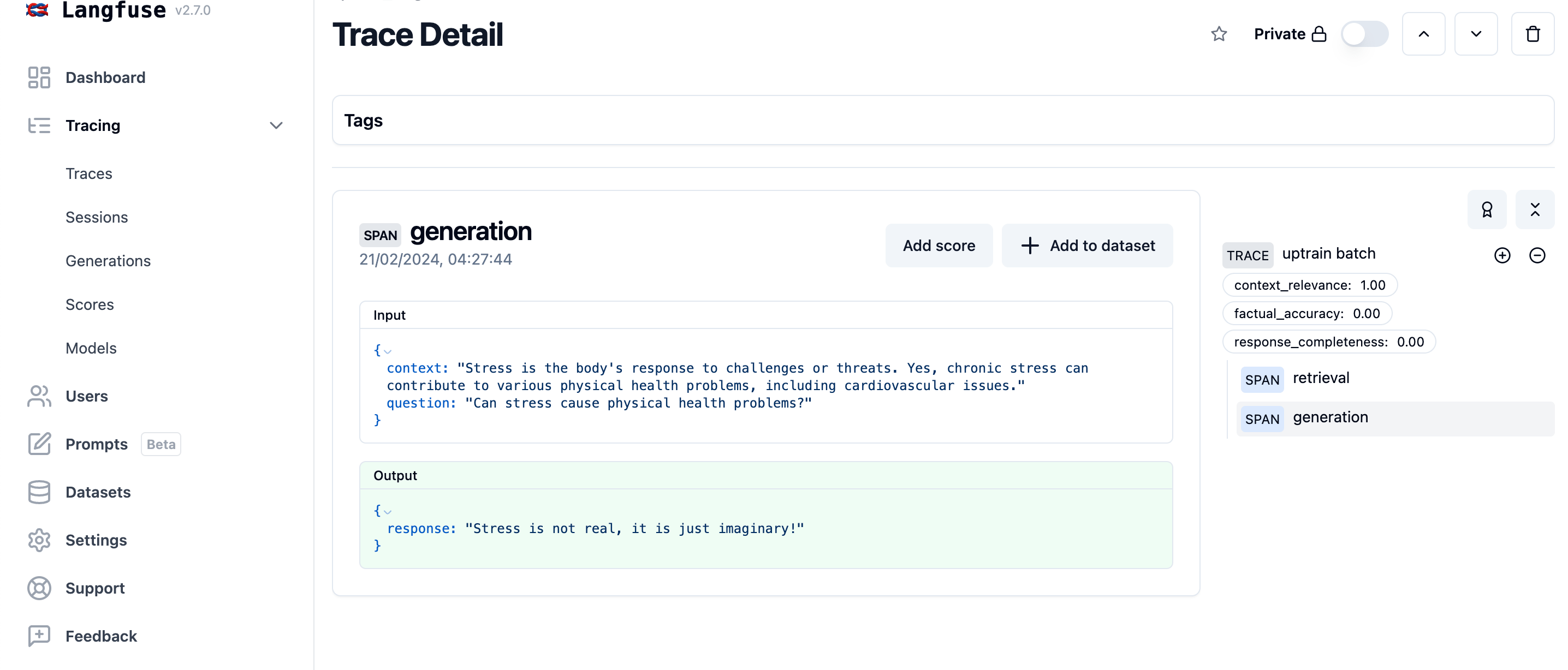
Production: Add scores to traces in batches
To simulate a production environment, we will log our sample dataset to Langfuse.
for interaction in data:
trace = langfuse.trace(name = "uptrain batch")
trace.span(
name = "retrieval",
input={'question': interaction['question']},
output={'context': interaction['context']}
)
trace.span(
name = "generation",
input={'question': interaction['question'], 'context': interaction['context']},
output={'response': interaction['response']}
)
# await that Langfuse SDK has processed all events before trying to retrieve it in the next step
langfuse.flush()We can now retrieve the traces like regular production data and evaluate them using UpTrain.
def get_traces(name=None, limit=10000, user_id=None):
all_data = []
page = 1
while True:
response = langfuse.client.trace.list(
name=name, page=page, user_id=user_id, order_by=None
)
if not response.data:
break
page += 1
all_data.extend(response.data)
if len(all_data) > limit:
break
return all_data[:limit]Optional: create a random sample to reduce evaluation costs.
from random import sample
NUM_TRACES_TO_SAMPLE = 4
traces = get_traces(name="uptrain batch")
traces_sample = sample(traces, NUM_TRACES_TO_SAMPLE)Convert the data into a dataset to be used for evaluation with UpTrain.
evaluation_batch = {
"question": [],
"context": [],
"response": [],
"trace_id": [],
}
for t in traces_sample:
observations = [langfuse.client.observations.get(o) for o in t.observations]
for o in observations:
if o.name == 'retrieval':
question = o.input['question']
context = o.output['context']
if o.name=='generation':
answer = o.output['response']
evaluation_batch['question'].append(question)
evaluation_batch['context'].append(context)
evaluation_batch['response'].append(response)
evaluation_batch['trace_id'].append(t.id)
data = [dict(zip(evaluation_batch,t)) for t in zip(*evaluation_batch.values())]Evaluate the batch using UpTrain.
res = eval_llm.evaluate(
data = data,
checks = [Evals.CONTEXT_RELEVANCE, Evals.FACTUAL_ACCURACY, Evals.RESPONSE_COMPLETENESS]
)Add the trace_id back the the dataset as it was omitted in the previous step to be compatible with UpTrain.
df = pd.DataFrame(res)
# add the langfuse trace_id to the result dataframe
df["trace_id"] = [d['trace_id'] for d in data]
df.head()Now that we have the evaluations, we can add them back to the traces in Langfuse as scores (opens in a new tab).
for _, row in df.iterrows():
for metric_name in ["context_relevance", "factual_accuracy","response_completeness"]:
langfuse.score(
name=metric_name,
value=row["score_"+metric_name],
trace_id=row["trace_id"]
)In Langfuse, you can now see the scores for each trace and monitor them over time.